Статический анализ Java-проектов с SonarQube в enterprise-среде
Статический анализ кода является стандартной практикой в крупных Java-проектах. Однако интеграция таких инструментов в существующие enterprise-системы часто оказывается сложнее, чем показано в документации.
Контекст задачи
По мере роста любой системы кодовая база неизбежно усложняется. Количество модулей увеличивается, появляются новые зависимости, архитектура постепенно обрастает историческими решениями. Даже при аккуратной разработке через несколько лет проект может содержать тысячи классов и десятки тысяч строк кода.
В таких системах ручной контроль качества становится все менее эффективным. Code review хорошо работает на уровне отдельных изменений, но не способен системно отслеживать общую деградацию качества кода.
Типичная картина для крупных Java-проектов выглядит примерно так:
- десятки Maven-модулей;
- тысячи классов и интерфейсов;
- несколько поколений библиотек;
- смешанные версии Java;
- legacy-зависимости, появившиеся в разные периоды развития системы.
Со временем это приводит к накоплению технического долга. В коде начинают появляться конструкции, которые формально работают, но создают потенциальные проблемы:
- возможные
NullPointerException; - некорректная работа с ресурсами;
- избыточная сложность методов;
- дублирование логики;
- использование устаревших API.
Такие проблемы редко выявляются в процессе обычного code review. Они не всегда очевидны и часто скрыты в деталях реализации.
Кроме того, ручная проверка кода плохо масштабируется. Чем больше становится система, тем сложнее разработчикам поддерживать единый стандарт качества и отслеживать архитектурные проблемы.
В результате возникает потребность в автоматизированном инструменте, который способен регулярно анализировать кодовую базу и выявлять потенциальные дефекты. Такой инструмент должен работать независимо от разработчиков и давать объективную картину состояния проекта.
Одним из наиболее распространенных решений для этой задачи является система статического анализа SonarQube.
Что решает статический анализ
Статический анализ кода — это автоматическая проверка исходников без запуска программы. Анализатор читает код, строит его внутреннее представление (AST) и применяет набор правил, позволяющих выявлять потенциальные проблемы.
В отличие от обычного code review, такой анализ выполняется регулярно и одинаково для всей кодовой базы. Это позволяет обнаруживать дефекты, которые могут оставаться незамеченными при ручной проверке.
Современные анализаторы способны выявлять несколько классов проблем.
Во-первых, это потенциальные ошибки в коде. Например, возможные NullPointerException, некорректное использование коллекций, неправильная работа с ресурсами или логические ошибки в условиях.
Во-вторых, анализаторы вычисляют метрики сложности кода. Слишком длинные методы, высокая вложенность условий или чрезмерная цикломатическая сложность ухудшают читаемость системы и значительно повышают стоимость сопровождения.
Третья категория — дублирование кода. В больших проектах одинаковая логика нередко копируется между модулями. Со временем это приводит к ситуации, когда исправление одной ошибки требует изменения сразу в нескольких местах.
Кроме того, статический анализ позволяет выявлять архитектурные проблемы. Например, использование устаревших API, нарушение инкапсуляции, чрезмерную связанность между модулями или неправильное использование библиотек.
Отдельное направление анализа связано с безопасностью. Анализаторы способны находить потенциальные уязвимости: небезопасную работу со строками, ошибки в обработке пользовательского ввода, использование слабых криптографических алгоритмов.
Важно понимать, что статический анализ не заменяет тестирование и мониторинг системы. Эти инструменты решают разные задачи.
- Unit-тесты проверяют корректность поведения конкретных компонентов системы.
- Интеграционные тесты проверяют взаимодействие между подсистемами.
- Runtime-мониторинг позволяет наблюдать за системой во время ее работы.
Статический анализ занимает другое место в этой цепочке. Он работает на уровне исходного кода и позволяет обнаруживать потенциальные проблемы еще до запуска приложения.
Архитектура SonarQube
SonarQube построен по достаточно простой архитектуре и состоит из двух основных компонентов: сервера анализа и инструмента, выполняющего анализ кода. При этом сама система является расширяемой — поддержку языков и дополнительных проверок обеспечивают плагины.
SonarQube Server
Сервер является центральным элементом системы. Именно он принимает результаты анализа, сохраняет их в базе данных и формирует интерфейс для просмотра метрик качества.
Внутри сервера можно выделить несколько ключевых подсистем.
Web-интерфейс предоставляет дашборды проекта, на которых отображаются метрики качества, найденные проблемы и история изменений кодовой базы. Через этот интерфейс разработчики могут анализировать результаты проверок и отслеживать динамику качества кода между коммитами.
Все результаты анализа сохраняются в базе данных. Она хранит информацию о проектах, метриках, найденных проблемах, истории анализов и состоянии quality gate.
Для ускорения поиска и агрегации данных используется встроенный Elasticsearch. Он индексирует результаты анализа и позволяет быстро строить отчеты по большим кодовым базам.
Каждый запуск анализа сохраняется как отдельная запись. Благодаря этому сервер может показывать историю изменений качества проекта и сравнивать разные версии кода.
Scanner
Scanner — это инструмент, который непосредственно выполняет анализ исходного кода. Он запускается либо локально на машине разработчика, либо в системе непрерывной интеграции.
Во время работы scanner выполняет несколько этапов.
Сначала он читает исходный код проекта и строит внутреннее представление программы. Для языков вроде Java анализатор строит AST (Abstract Syntax Tree) — синтаксическое дерево, отражающее структуру кода.
После этого применяются правила анализа. На этом этапе вычисляются метрики сложности, ищутся потенциальные ошибки, обнаруживаются дублирования кода и другие проблемы.
Когда анализ завершен, scanner формирует отчет и отправляет его на сервер SonarQube. Сервер обрабатывает полученные данные, сохраняет их в базе и обновляет дашборды проекта.
Важно, что scanner не хранит результаты анализа локально — он выполняет только вычислительную часть работы.
Плагины языков
Поддержка различных языков и типов файлов в SonarQube реализована через систему плагинов.
Каждый плагин содержит набор правил анализа и механизм разбора соответствующего языка. Например, Java-плагин умеет строить AST для Java-кода и проверять его на соответствие сотням правил.
Помимо языковых плагинов существуют специализированные анализаторы. Например, плагины могут проверять XML-файлы конфигурации, Docker-файлы, инфраструктурные скрипты или искать потенциальные утечки секретов в коде.
Благодаря такой архитектуре SonarQube может анализировать не только исходный код приложения, но и значительную часть инфраструктурных файлов проекта.
Развертывание сервера
Развертывание SonarQube не требует сложной инфраструктуры и может быть выполнено на обычной виртуальной машине. Для небольших команд и тестовых стендов достаточно одного сервера, на котором будут запущены все компоненты системы.
Требования
Минимальные требования к серверу достаточно умеренные, однако важно учитывать, что SonarQube активно использует Elasticsearch и хранит историю анализов. Это означает, что требования к памяти и дисковому пространству со временем растут.
Основные требования включают:
- установленную Java (обычно поддерживаемые LTS-версии);
- достаточный объем оперативной памяти для работы сервера и Elasticsearch;
- дисковое пространство для хранения истории анализов;
- доступную базу данных.
В тестовых окружениях часто используется встроенная база данных, которая поставляется вместе с SonarQube. Она подходит для локального использования и пилотных внедрений.
В production-среде обычно используется внешняя база данных (например PostgreSQL), поскольку встроенная база не предназначена для длительного хранения больших объемов данных.
Минимальный запуск
Минимальный запуск SonarQube сводится к распаковке дистрибутива и запуску сервера.
После загрузки архива необходимо перейти в каталог с исполняемыми скриптами:
1
cd sonarqube/bin/linux-x86-64
Далее сервер запускается стандартным скриптом:
1
./sonar.sh start
После запуска веб-интерфейс становится доступен по адресу:
1
http://<host>:9000
При первом входе используется стандартная пара логина и пароля:
1
admin / admin
После авторизации SonarQube предложит сменить пароль администратора.
На этом этапе сервер уже готов принимать результаты анализа.
systemd-сервис
Для постоянной эксплуатации сервер обычно запускается как системный сервис. Это позволяет автоматически запускать SonarQube при старте системы и управлять сервисом стандартными средствами Linux.
Пример unit-файла systemd может выглядеть следующим образом:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
[Unit]
Description=SonarQube service
After=network.target
[Service]
Type=forking
ExecStart=/opt/sonarqube/bin/linux-x86-64/sonar.sh start
ExecStop=/opt/sonarqube/bin/linux-x86-64/sonar.sh stop
User=sonarqube
Restart=always
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
После создания unit-файла сервис можно зарегистрировать в системе:
1
2
3
systemctl daemon-reload
systemctl enable sonarqube
systemctl start sonarqube
После этого сервер будет автоматически запускаться вместе с системой.
Доступ пользователей
После развертывания сервера необходимо определить, каким образом разработчики будут получать доступ к результатам анализа.
В простейшем варианте достаточно открыть веб-интерфейс SonarQube для чтения. Пользователи смогут просматривать дашборды проектов, анализировать найденные проблемы и отслеживать динамику метрик качества.
Для более сложных сценариев можно настроить:
- регистрацию пользователей;
- интеграцию с корпоративной системой аутентификации (LDAP);
- различные уровни доступа к проектам.
На практике чаще всего используется простая схема: анализ выполняется автоматически через CI, а разработчики используют веб-интерфейс SonarQube только для просмотра результатов.
Способы запуска анализа
Анализ проекта в SonarQube может запускаться несколькими способами. На практике используются два основных подхода: запуск анализа через Maven-плагин или использование отдельного инструмента Sonar Scanner.
Оба варианта выполняют одну и ту же задачу — анализируют исходный код проекта и отправляют результаты на сервер SonarQube. Однако их интеграция в сборку и взаимодействие с проектом отличаются.
Maven plugin
Наиболее очевидный способ запуска анализа для Maven-проектов — использование Maven-плагина SonarQube.
Запуск анализа выполняется отдельной целью Maven:
1
mvn sonar:sonar
Плагин интегрируется непосредственно в процесс сборки проекта. Он использует конфигурацию Maven, читает структуру модулей, зависимости и автоматически определяет расположение исходников и скомпилированных классов.
В типичном сценарии процесс выглядит следующим образом:
- Maven собирает проект.
- Плагин анализирует исходный код.
- Результаты анализа отправляются на сервер SonarQube.
Такой способ удобен тем, что анализ становится частью стандартного процесса сборки. Его легко встроить в pipeline CI и запускать автоматически при каждой сборке.
Однако у этого подхода есть и обратная сторона. Поскольку анализ выполняется внутри Maven-процесса, он полностью зависит от того, насколько корректно собирается сам проект. Если сборка не проходит или содержит нестабильные модули, запуск анализа также завершится ошибкой.
Sonar Scanner CLI
Альтернативный способ запуска анализа — использование отдельного инструмента Sonar Scanner CLI.
В этом случае анализ выполняется отдельной программой:
1
sonar-scanner
Scanner работает независимо от системы сборки проекта. Он читает исходный код и использует уже скомпилированные классы, которые обычно находятся в каталоге target/classes.
Типичный сценарий запуска выглядит так:
- проект компилируется обычной сборкой;
- scanner анализирует исходный код;
- результаты отправляются на сервер SonarQube.
Таким образом, процесс анализа становится независимым от Maven-плагинов и внутренней структуры сборки.
Почему существуют оба подхода
Оба способа запуска анализа исторически решают разные задачи.
Maven-плагин удобен для проектов со стабильной сборкой и хорошо подходит для небольших сервисов или микросервисных приложений. В таких проектах анализ можно просто добавить в pipeline CI и запускать вместе с обычной сборкой.
Sonar Scanner CLI обеспечивает более гибкий подход. Поскольку он работает отдельно от системы сборки, его проще использовать в сложных проектах с большим количеством модулей, нестандартной конфигурацией Maven или legacy-зависимостями.
На практике выбор между этими способами часто определяется не удобством использования, а особенностями конкретной кодовой базы.
Проблемы Maven-плагина
На первый взгляд использование Maven-плагина для запуска анализа выглядит самым естественным решением. Достаточно добавить цель sonar:sonar в pipeline сборки, и анализ будет автоматически выполняться вместе с компиляцией проекта.
Однако в крупных и особенно legacy-проектах этот подход часто сталкивается с неожиданными проблемами. Причина в том, что Maven-плагин выполняется внутри процесса сборки и полностью зависит от ее окружения.
Если сборка проекта нестабильна или содержит устаревшие зависимости, запуск анализа также становится нестабильным.
Ниже рассмотрены несколько типичных проблем, которые могут возникнуть при использовании Maven-плагина SonarQube.
Несовместимость версий Java
Одной из самых частых проблем является несовместимость версий Java между проектом и плагином анализа.
Например, многие крупные системы до сих пор собираются под Java 8, в то время как современные версии Sonar-плагинов компилируются под более новые версии Java.
В этом случае Maven может завершиться ошибкой загрузки плагина:
1
UnsupportedClassVersionError
Такая ошибка означает, что класс был скомпилирован для более новой версии JVM, чем та, которая используется во время сборки проекта.
Фактически возникает конфликт двух требований:
- код проекта должен компилироваться под старую версию Java;
- плагин анализа требует более новую JVM.
В результате Maven не может загрузить плагин и анализ не запускается.
Legacy-зависимости (tools.jar)
Во многих старых проектах можно встретить зависимость:
1
com.sun:tools
Исторически она указывала на файл tools.jar, который поставлялся вместе с JDK до Java 8. Этот файл содержал инструменты компиляции и некоторые внутренние API JDK.
Начиная с Java 9 структура JDK была полностью переработана, а tools.jar исчез из дистрибутива. Соответственно, попытка собрать проект с такой зависимостью под современной JVM приводит к ошибке разрешения зависимостей.
Интересно, что подобная зависимость может быть добавлена не напрямую, а приходить транзитивно из старых библиотек или внутренних модулей системы.
Пока сборка выполняется под Java 8, проблема может оставаться незаметной. Однако при попытке запустить анализ под более новой JVM Maven начинает искать файл tools.jar в каталоге JDK и не находит его.
Multi-module reactor build
Еще одна особенность Maven-плагина связана с тем, как работает reactor build.
В проектах с большим количеством модулей структура сборки может выглядеть примерно так:
1
2
3
4
5
6
root
├─ module-core
├─ module-integration
├─ module-service
├─ module-tests
└─ module-distribution
Когда запускается команда
1
mvn sonar:sonar
Maven выполняет анализ всего reactor-проекта. Это означает, что анализ будет выполняться последовательно для каждого модуля.
Если хотя бы один модуль не собирается — например из-за отсутствующей зависимости или нестабильных тестов — выполнение всей команды прерывается. В результате анализ кода не выполняется даже для тех модулей, которые собираются корректно.
В больших системах с десятками модулей это делает запуск анализа через Maven значительно менее надежным.
Несовместимость Maven-плагинов
Дополнительные сложности могут возникать из-за устаревших Maven-плагинов, используемых в проекте.
В legacy-кодовых базах нередко встречаются плагины старых версий:
- старые версии
maven-compiler-plugin; - устаревшие плагины генерации кода;
- плагины, использующие внутренние API Maven.
Поскольку Sonar-плагин выполняется внутри того же процесса сборки, любые проблемы совместимости между плагинами могут влиять и на запуск анализа.
В результате даже корректная конфигурация SonarQube не гарантирует, что анализ будет успешно выполняться в рамках Maven-сборки.
Использование Sonar Scanner CLI
Проблемы, возникающие при использовании Maven-плагина, связаны с тем, что анализ выполняется внутри процесса сборки. Это делает его чувствительным к любым особенностям конфигурации Maven, версиям Java и устаревшим зависимостям.
Альтернативным способом запуска анализа является использование отдельного инструмента Sonar Scanner CLI.
В этом случае анализ выполняется как независимый процесс и не зависит от плагинов системы сборки. Scanner просто читает исходный код проекта и использует уже скомпилированные классы, которые были получены на предыдущем этапе сборки.
Такой подход значительно упрощает интеграцию анализа в сложных или legacy-проектах.
Принцип работы
При использовании CLI анализ отделяется от этапа компиляции. Сначала проект собирается обычным способом, после чего запускается анализ.
Схема работы выглядит следующим образом:
1
compile → analyze
Это означает, что система сборки используется только для компиляции проекта, а анализ выполняется отдельным инструментом.
Scanner анализирует:
- исходный код проекта;
- скомпилированные
.classфайлы; - структуру каталогов проекта.
Полученные данные преобразуются в отчет, который отправляется на сервер SonarQube.
Поскольку scanner не участвует в процессе сборки, любые проблемы с Maven-плагинами или legacy-зависимостями не влияют на выполнение анализа.
Конфигурация
Конфигурация анализа выполняется через файл:
1
sonar-project.properties
Этот файл размещается в корне проекта и содержит основные параметры анализа.
Минимальная конфигурация может выглядеть следующим образом:
1
2
3
4
5
6
7
8
sonar.projectKey=example-project
sonar.projectName=Example Project
sonar.sources=src
sonar.java.binaries=target/classes
sonar.host.url=http://sonar-server:9000
sonar.login=<token>
Параметр sonar.sources указывает каталоги с исходным кодом, а sonar.java.binaries — расположение скомпилированных классов.
Scanner использует эти данные для построения модели проекта и последующего анализа.
Запуск анализа
После настройки конфигурации анализ запускается одной командой:
1
sonar-scanner
Во время выполнения scanner выполняет несколько этапов:
- читает конфигурацию проекта;
- анализирует структуру исходного кода;
- применяет правила анализа;
- формирует отчет;
- отправляет результаты на сервер SonarQube.
После завершения анализа сервер обрабатывает полученные данные, обновляет метрики проекта и формирует дашборды качества.
Таким образом, использование Sonar Scanner CLI позволяет отделить анализ кода от процесса сборки и значительно упростить его запуск в сложных проектах.
Типичные проблемы при анализе больших проектов
При анализе небольших сервисов SonarQube обычно работает достаточно предсказуемо. Однако в крупных кодовых базах анализ может сталкиваться с рядом проблем, связанных с особенностями проекта, историческими зависимостями и большим количеством вспомогательных файлов.
Ниже рассмотрены несколько типичных ситуаций, которые часто возникают при анализе больших систем.
Кодировки файлов
В старых проектах нередко встречается смешанное использование кодировок. Часть файлов может быть сохранена в UTF-8, часть — в Windows-1251 или других локальных кодировках.
Во время анализа это может приводить к ошибкам вида:
1
Invalid character encountered
Такая ошибка означает, что анализатор пытается прочитать файл как UTF-8, но встречает байтовую последовательность, которая не соответствует этой кодировке.
Чаще всего подобная проблема возникает в:
- XML-файлах конфигурации;
- старых XSD-схемах;
- тестовых ресурсах;
- скриптах миграции.
Обычно она решается явным указанием кодировки проекта:
1
sonar.sourceEncoding=UTF-8
Либо исключением отдельных файлов из анализа.
Анализ XML и XSD
В больших enterprise-проектах значительная часть логики может быть вынесена в XML-конфигурацию. Это могут быть:
- схемы интеграции;
- XSD-описания сообщений;
- конфигурации трансформаций;
- различные справочники и шаблоны.
SonarQube пытается анализировать такие файлы с помощью соответствующих плагинов. Однако большое количество XML-ресурсов может существенно увеличивать время анализа.
Кроме того, некоторые XML-файлы могут быть слишком специфичными для стандартных анализаторов. В этом случае scanner может выводить предупреждения о невозможности разобрать файл.
Если такие файлы не представляют интереса с точки зрения анализа качества кода, их обычно исключают из анализа через настройки sonar.exclusions.
CPD detector
Одной из функций SonarQube является обнаружение дублирования кода. Для этого используется механизм CPD (Copy-Paste Detector).
Иногда анализатор дублирования может завершаться ошибкой вида:
1
DuplicationsException
Как правило, это связано с тем, что CPD не смог корректно разобрать один из файлов. Причиной может быть нестандартный синтаксис, автоматически сгенерированный код или специфические конструкции языка.
В подобных случаях проблемный файл также можно исключить из анализа. Это позволяет продолжить выполнение анализа для остальной части проекта.
Время анализа
Еще одной особенностью больших проектов является длительное время анализа.
Если кодовая база содержит:
- тысячи классов;
- десятки Maven-модулей;
- большое количество ресурсов;
- XML и XSD-схемы,
анализ может занимать несколько минут даже на достаточно мощной машине.
Это связано с тем, что scanner выполняет достаточно сложные операции:
- построение AST для исходного кода;
- вычисление метрик сложности;
- поиск дублирования;
- анализ зависимостей между классами;
- обработку большого количества файлов ресурсов.
Поэтому время анализа растет примерно пропорционально размеру кодовой базы.
В CI-системах это необходимо учитывать при планировании pipeline. Иногда анализ выполняется не для каждого коммита, а только для определенных веток или ночных сборок.
Интеграция в CI
После того как сервер SonarQube развернут и анализ проекта настроен, следующим шагом обычно становится интеграция анализа в CI.
В большинстве проектов анализ выполняется автоматически при каждой сборке. Типичный pipeline выглядит примерно так:
1
2
3
4
5
6
7
8
9
git push
↓
CI build
↓
compile
↓
sonar analysis
↓
quality gate
Таким образом, каждый коммит в репозиторий приводит к запуску анализа кода. Это позволяет регулярно получать актуальные метрики качества и быстро обнаруживать появление новых проблем.
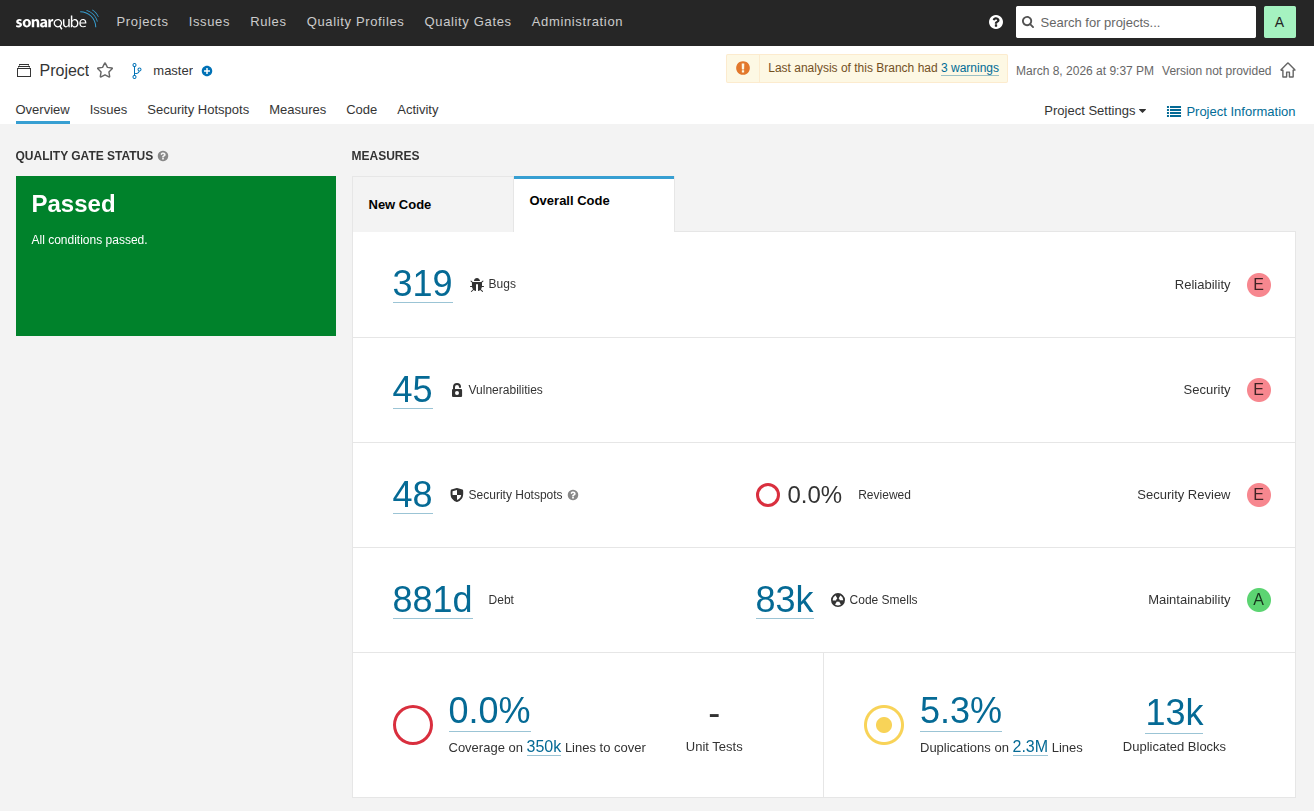
Дашборд проекта в SonarQube. Отображаются основные метрики качества: bugs, vulnerabilities, code smells, покрытие тестами и дублирование кода.
Запуск анализа на CI
В системе непрерывной интеграции анализ обычно выполняется как отдельный шаг pipeline.
Типичная последовательность действий выглядит следующим образом:
- система CI получает изменения из репозитория;
- выполняется сборка проекта;
- запускается анализ кода через Sonar Scanner;
- результаты отправляются на сервер SonarQube.
В простейшем случае запуск анализа выглядит так же, как и локально:
1
sonar-scanner
Все параметры подключения к серверу, такие как URL SonarQube и токен авторизации, передаются через переменные окружения или конфигурационные файлы CI.
Поскольку scanner работает независимо от системы сборки, его можно запускать практически в любой CI-системе.
Хранение результатов
После завершения анализа scanner отправляет отчет на сервер SonarQube. Сервер сохраняет результаты в базе данных и обновляет индексы поиска.
Каждый запуск анализа сохраняется как отдельная запись. Благодаря этому SonarQube может показывать:
- историю анализов проекта;
- динамику изменения метрик качества;
- появление новых проблем в коде.
Например, можно увидеть, в каком коммите появилась конкретная проблема или как менялось количество дублирования кода между версиями проекта.
Такой подход позволяет использовать SonarQube не только как инструмент анализа, но и как систему наблюдения за качеством кодовой базы.
Влияние на сборку
Интеграция анализа в CI позволяет использовать результаты проверки для контроля качества сборки.
В SonarQube существует механизм Quality Gate — набор правил, которым должен соответствовать проект. Например:
- отсутствие новых ошибок;
- отсутствие уязвимостей;
- минимальный уровень покрытия тестами.
Если анализ показывает, что проект не проходит Quality Gate, система CI может пометить сборку как неуспешную.
Таким образом, анализ кода становится частью автоматического контроля качества. Новые изменения не могут быть приняты в систему, если они ухудшают состояние кодовой базы.
Quality Gates и работа с результатами анализа
Одним из ключевых механизмов SonarQube является Quality Gate. Это набор правил, которым должен соответствовать проект после выполнения анализа.
Quality Gate используется как автоматический контроль качества кода. Если проект нарушает заданные правила, анализ считается неуспешным, а CI-система может пометить сборку как failed.
Типичные правила Quality Gate включают:
- отсутствие новых ошибок (
bugs); - отсутствие уязвимостей (
vulnerabilities); - ограничение на количество новых code smells;
- минимальный уровень покрытия тестами (
coverage); - ограничение на дублирование кода (
duplication).
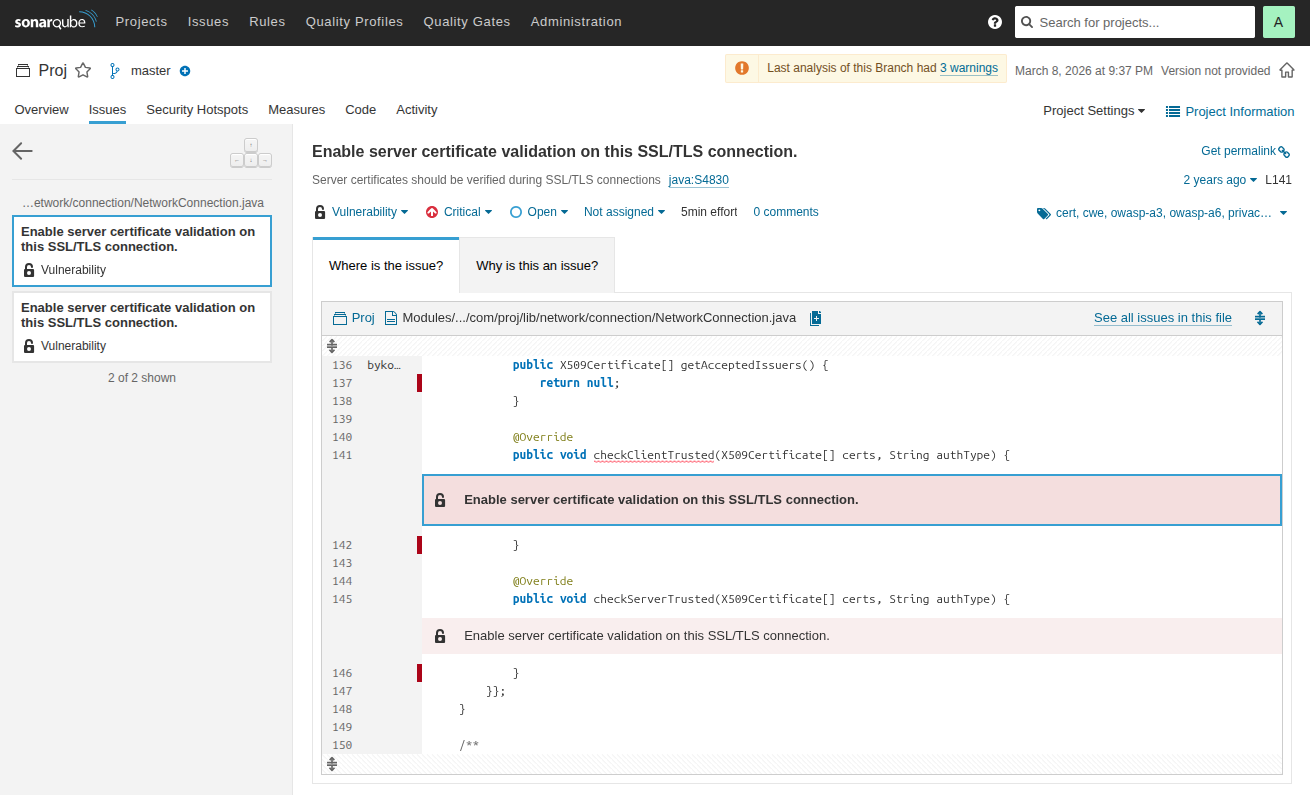
Пример обнаруженной уязвимости: отсутствие проверки сертификата при установлении SSL-соединения.
Важно понимать, что Quality Gate обычно применяется не ко всей кодовой базе, а только к новому коду. Такой подход позволяет постепенно улучшать качество системы, не пытаясь сразу исправить весь накопленный технический долг.
Эта стратегия известна как Clean as You Code. Ее идея заключается в том, что новый код должен быть чистым и не добавлять новых проблем, даже если в существующей кодовой базе они уже присутствуют.
Практический workflow работы с анализом
После интеграции SonarQube в CI анализ становится регулярной частью процесса разработки. Типичный workflow работы с результатами анализа выглядит следующим образом.
Сначала выполняется анализ проекта. Это происходит автоматически при сборке в CI или вручную при запуске scanner.
После завершения анализа SonarQube формирует список найденных проблем. Они классифицируются по типу (bug, vulnerability, code smell) и уровню серьезности.
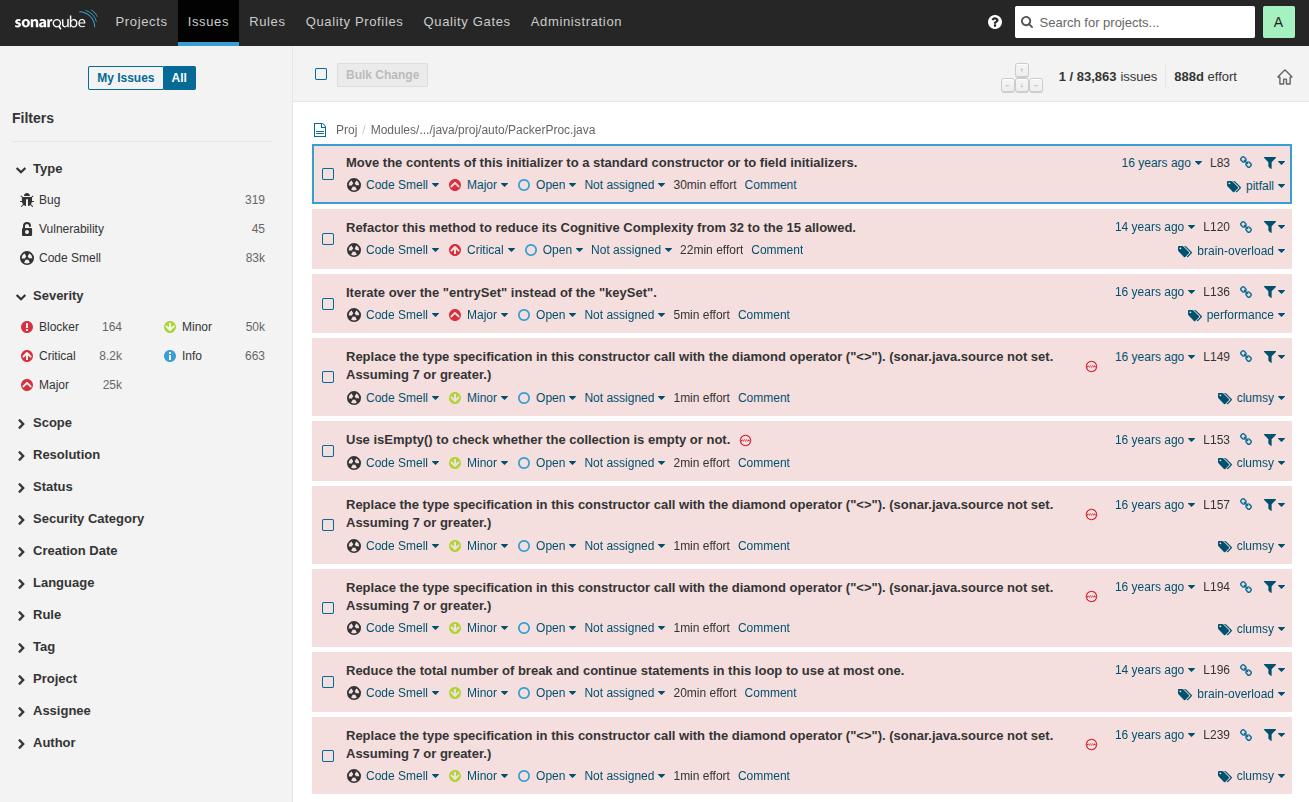
Пример списка проблем, найденных анализатором. Каждая запись содержит тип проблемы, уровень серьезности и оценку трудозатрат на исправление.
Разработчик может просмотреть результаты анализа через веб-интерфейс SonarQube. Для каждой проблемы отображается ее описание, место в коде и рекомендации по исправлению.
Если проблема требует изменения кода, обычно создается отдельная задача в системе трекинга. Это позволяет включить исправление в обычный процесс разработки.
После внесения изменений код повторно проходит анализ. Если проблема была исправлена, она автоматически исчезает из отчета SonarQube.
Таким образом, статический анализ постепенно становится частью обычного цикла разработки. Новые проблемы обнаруживаются автоматически, а качество кодовой базы со временем улучшается.
Практическая польза статического анализа
Внедрение статического анализа не является универсальным решением всех проблем качества кода. Однако в крупных системах он становится важным инструментом контроля состояния кодовой базы.
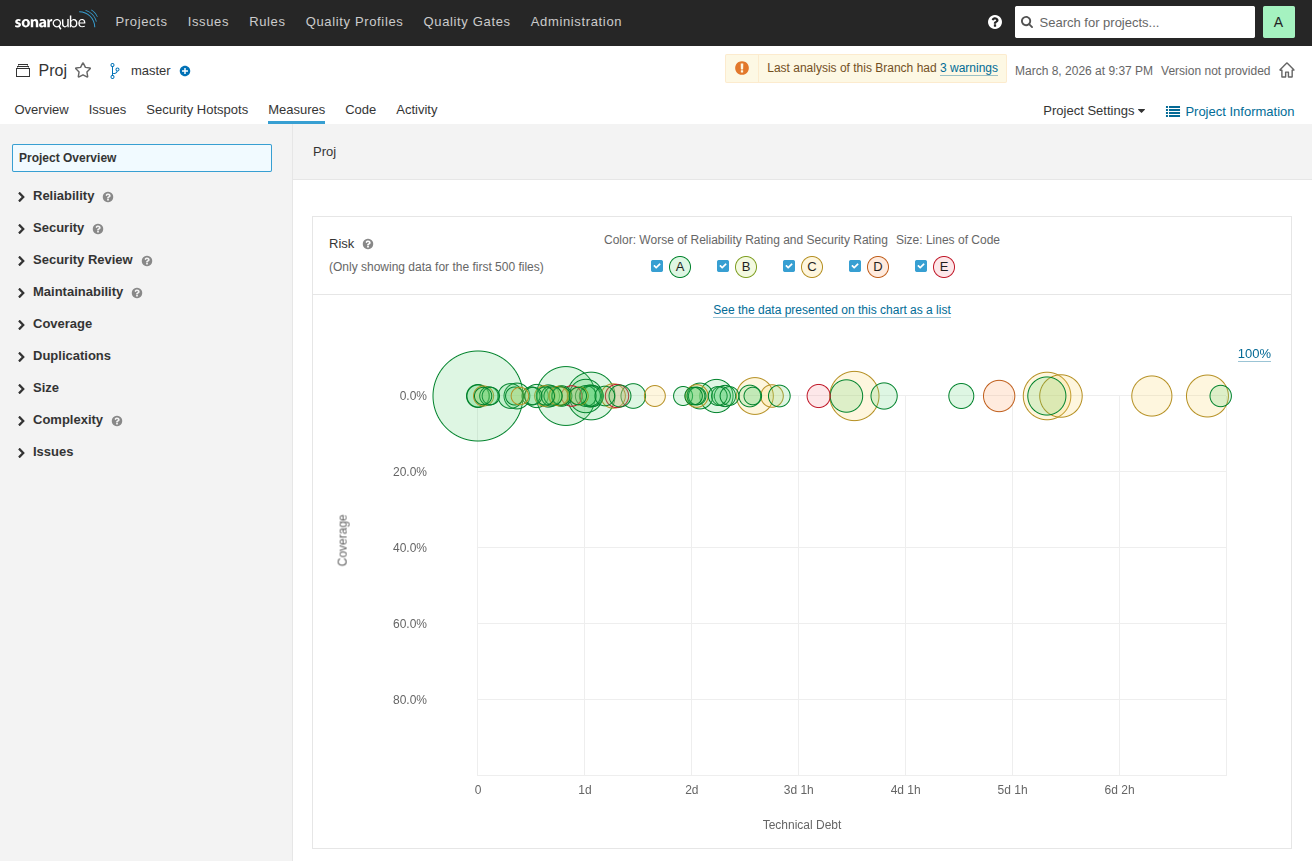
Визуализация метрик проекта: размер кружков соответствует количеству строк кода, цвет — уровню проблем качества.
Основное преимущество такого подхода заключается в регулярности анализа. Проверка выполняется автоматически и одинаково для всей системы, что позволяет выявлять проблемы, которые трудно заметить в процессе обычного code review.
В больших проектах статический анализ помогает решать несколько практических задач.
Во-первых, он позволяет обнаруживать потенциальные ошибки на ранней стадии. Такие проблемы, как возможные NullPointerException, неправильная работа с ресурсами или подозрительные конструкции в коде, могут быть выявлены еще до запуска приложения.
Во-вторых, анализаторы помогают контролировать сложность системы. Метрики сложности и дублирования кода дают объективное представление о состоянии проекта и позволяют отслеживать его эволюцию.
Еще одной важной задачей является контроль технического долга. Со временем даже аккуратно разработанные системы начинают накапливать устаревшие решения и дублирующуюся логику. Регулярный анализ позволяет отслеживать появление новых проблем и постепенно улучшать качество кодовой базы.
Особенно полезным статический анализ оказывается в больших командах. Когда над системой работают десятки разработчиков, автоматический контроль качества помогает поддерживать единые стандарты кода и снижает зависимость от ручной проверки.
Таким образом, SonarQube можно рассматривать не только как инструмент поиска ошибок, но и как средство наблюдения за состоянием проекта. Интеграция анализа в CI позволяет регулярно получать объективную картину качества кода и своевременно реагировать на появление новых проблем.